
LLM
综述
- agent
- 提示词prompt
- 工作流搭建
- 模型部署和高并发(资源优化和分配)
- 开发框架
- langchain
- pytorch
- tensorflow
- hugginface
- 模型训练与微调
- 高质量微调数据与评估
- 微调原理
- LLM蒸馏 (大模型到小模型)
- 多模态
- 知识库搜索
- Embbedings和向量库
- RAG技术
- RAG多模态处理
- RAG调优
- AI Coding
- 如何使用和经验
- AI开发与AI重构
- 分工与协作:前端、后段、产品经理
- 部署Claude Code (信创要求高: 国央企、军队)
几个模型大厂和六小厂
云计算、GPU租赁:阿里云、火山引擎、AutoDL
OPC(一个人公司,one person company)
行业场景
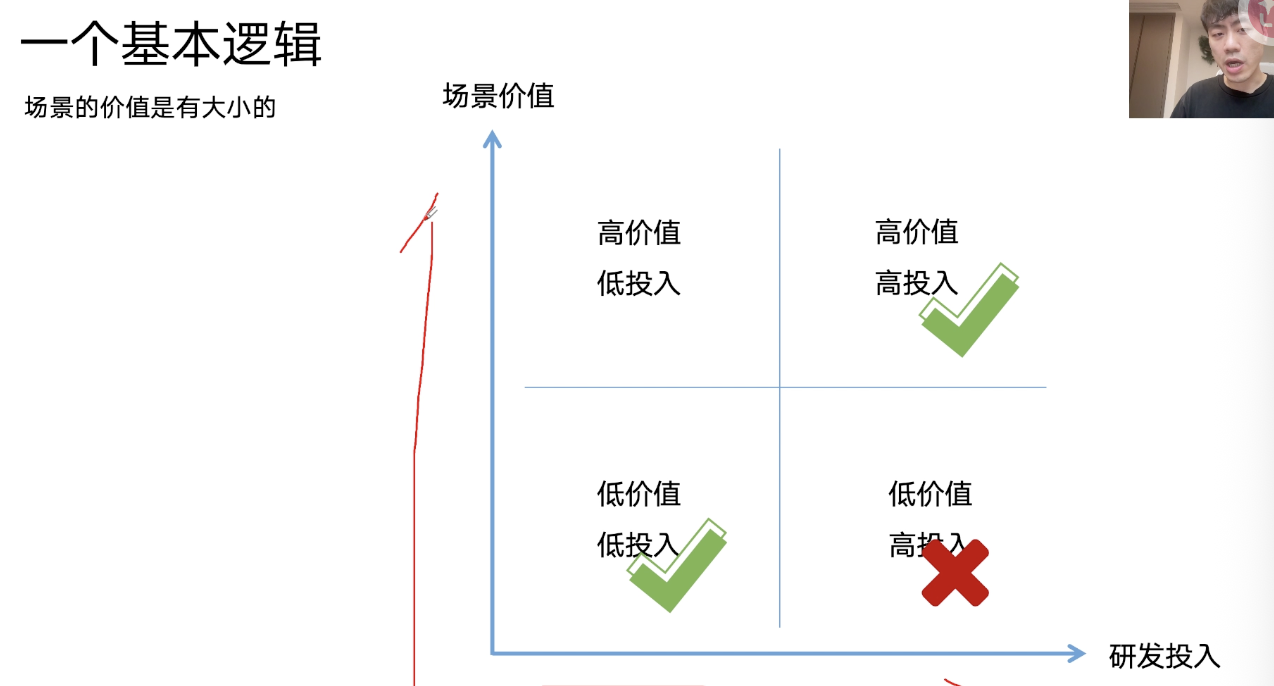

2C企业:
需要流量、成交口碑、副购、成本,
低价值低投入场景:文案、图片生成、数字人、网络信息搜索、对话数据解析、模版文件处理、软件操作、票据处理、简历面试
高价值高投入:图片定制生成、营销视频、视频行为分析、在线客服/销售、个性化服务、声音合成、产品效果展示、产品创意设计、合规审查、数据可视化、企业知识库
模型能力不行时需要工程应用处理
2B企业(生产性企业,利润低):
需求:稳定生产、提高效率、降低成本
低价值低投入:生产计划、采购计划、市场数据抓取、系统软件操作
高价值高投入:生产质量、生产设备监测、视频行为分析、原料消耗管理、调度物流配置、仓储管理、价格预测
服务企业:
需求:升级产品和服务、提升竞争力、降低服务成本、推出AI新产品和新服务
国央企:
需求:优化资源配置、提高办事效率、加快响应速度、安全防护

提示词工程
系统提示词和用户提示词,prompt是与LLM打交道的唯一方式。应用层的技术是为了拼出一个合适的promt。
- 身份设定
- 背景设定
- 参考资料
- 样例
- 没有样例:Zero-Shot
- 一个样例:One-Shot
- 多个样例:Few-Shot
- 如何动态添加样例而不是手写样例
- RAG:Retrieval-Augmented Generation(回答问题之前先做一轮内部知识搜索)
- 将参考资料和样例放在prompt中,就叫做In-Context-Learning(下一轮对话需要注入上下文,否则会忘掉)
- 模型接收提示词有字数限制,且内容多性能下降,需要知识库塞入这些内容。
- 构建知识库:
- 分析场景是宽场景还是窄场景
- 搜集文件(pdf、word、md、html、表格、图片)并纯文字化-》
- 分块/切片(100~2000文字)(ai、agent、人工)-〉
- 技巧:每一个切片是一个对立的主题(一行一个主题)
- 技巧:人为切分固定数量的文本
- 技巧:问答对格式,一个问答对为一个chunk,优先使用rag而不是微调
- 向量化embedding和存储
- 优化检索结果
- 没有检索到
- 检索到了但是相似度不高
- LLM调用知识库:
- 用户query-》向量化embedding
- 在向量库中搜索相似的向量
- 拼接提示词(系统提示词+搜索到的知识向量+原始query向量)=》最终提示词
- 最终提示词给LLM并给出反馈
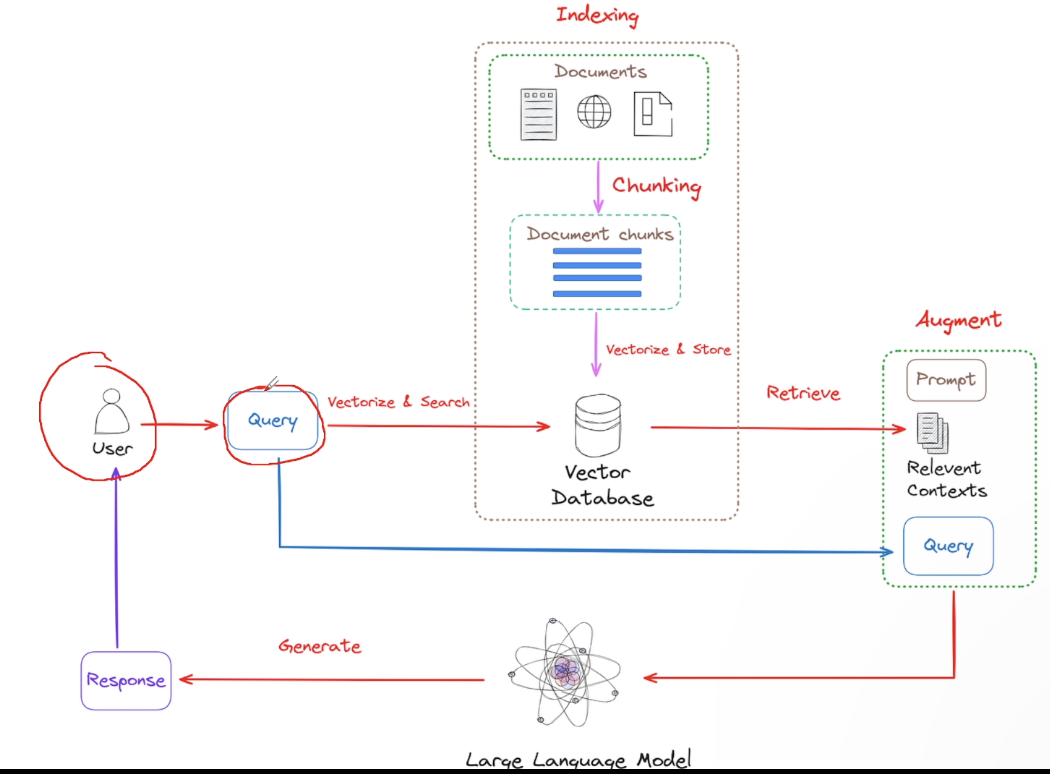
- RAG:Retrieval-Augmented Generation(回答问题之前先做一轮内部知识搜索)
- 指令
- 限制条件
RAG的高级技巧:双向奔赴
用户的query如何在向量库中找出来对应的信息,
融合策略:
- Query改写(依靠LLM):
- 汇总上下文信息,总结用户核心诉求作为query
- query默认是用户问题
- query的样式多种多样
- 用户会多轮的形式提问
- 多意图query
- 反问型query
- 条件型query,哪些需要检索知识库哪些检索数据库
- 模糊指代型query
- 对比型query
- 上下文依赖型query
- Agentic RAG:在检索RAG前agent判断是否进行改写query,针对上下文分析对RAG检索几次,如何拼接成提示词
- 汇总上下文信息,总结用户核心诉求作为query
- 知识库处理技巧
- 对场景的理解:清除用户会问什么,怎么问
- 对技术的理解:问题的分类、不同问题对应的知识库、每个知识库的知识处理方式
- 举例:
- coze知识库 爬虫-》转纯文本txt,
- 知识和问题内容不对等、长度不对等,需要使用excel表格填充问题和知识内容对,用LLM根据知识内容生成用户问题
- 将问题变成数学向量放入向量库并加入meta信息(即对应的知识出处,创建时间、元文字的其他信息)
- 微信对答知识库
- 问答对(多个问题一个回答)
- 长视频知识库
- 视频变成文字处理方式:
- 视频归类
- 演讲类画面不重要音频为重
- 找一个工具分离出音频
- 找一个工具把声音转成文字(一般6万到8万字)
- 切片(LLM辅助切片,观察数据梳理数据:例如最小颗粒度的知识点不会超过1000个文字),先取1000个字,让LLM分析讲了几个主题,将第一个主题的文字长度输出出来,再从第一个主题后的第一个文字开始取1000个文字,重复上述工作
- 如果LLM切的不好,你要通过提示词告诉它你的主题是如何定义的
- 三元组(问题、知识内容、图片),问题放入向量库并把知识和图片放入向量对应的meta元文字中
- 视频画面传递信息
- 两种类型交替出现(切割视频)
- 演讲类画面不重要音频为重
- 视频归类
- 视频变成文字处理方式:
- coze知识库 爬虫-》转纯文本txt,
- 举例:
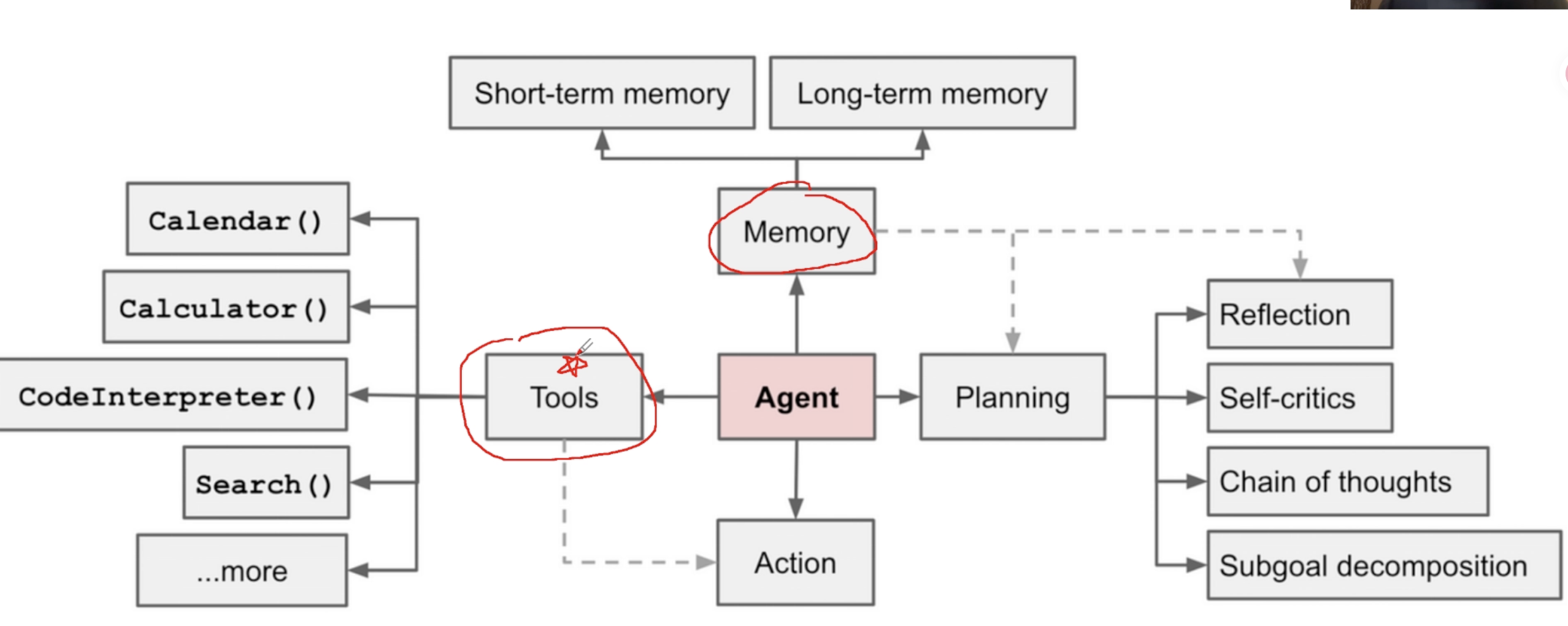
Agent
workflow agent 工作流智能体
设计agent时要给大语言模型多大的空间
- LLM幻觉
- LLM只会说,不会做
- LLM规划的步骤不可靠
如何应对极强的准确度、可控性=》模型提供智能,agent保证结果。 - 意图识别,分流(function call)
- 对其中每种意图做工作流(功 能模块)或者skill
问:例如五道口有地铁站吗
操作:
1、检索知识库
2、执行工作流(地点意图)
得到两个结果,检索知识库的回答结果和工作流输出结果。将两个结果拼成最终的提示词给LLM让它给出反馈结果。
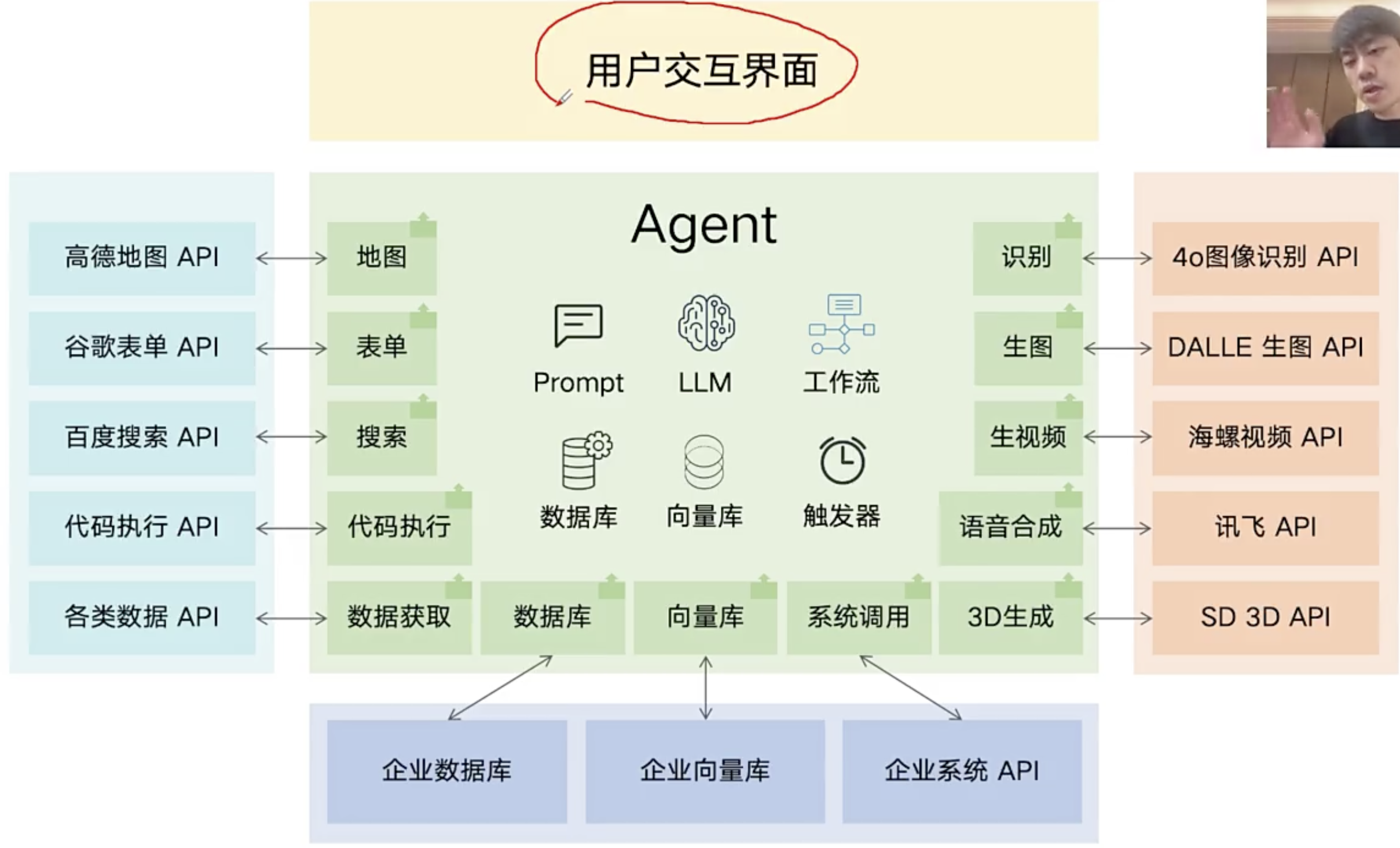
工作流和skill
工作流和skill是提前开发好的功能模块,大语言模型有function call能力(大语言模型能够看到用户的自然语言命令、要求和问题,并有能力自主判断是否要调用某个功能模块(工具)、调用哪些功能模块、调用工具时的参数是什么),但是你要把这些可被调用的工具写到系统提示此中,否则大语言模型不知道都有哪些工具可被它支配。
react agent 推理型智能体
通用agent例如open claw龙虾、permis爱马仕、manus、codex、claude使用推理智能体。
专用agent例如某个场景无自主性,工作流智能体。
有些任务无法提前设定步骤怎么办?
react:reasoning+acting:推理(要采用什么行动)、行动、整理并获得反馈,三者多轮循环,每轮循环都在更新拼接新的提示词。
推理阶段:
- LLM推理使用哪个工具。返回文本
- 我们要给出若干可用的行动工具skill到系统提示词中,让大语言从里面挑选。
- 输出行动的名称。
行动阶段: - 提前写好的行动代码(可以是人也可以是LLM写)
反馈阶段: - agent拼接提示词
例如AutoGPT
模版提示词拼接内容:
三个板块
- 引导LLM思考
- 列出所有行动工具:ListFileNames、AskDocument
- 输出的内容是当前最新的任务执行记录
模拟循环过程:
- step0:
- 原始提示词
- LLM给出调用工具文本名
{"action": ListFileNames} - agent执行
ListFileNames,返回文本
1 | 各类电子产品销售数据.xlsx |
- step 1:
- 新的拼接提示词=原始提示词+上轮返回的文本
1 | 各类电子产品销售数据.xlsx |
- LLM给出调用工具文本
1 | { |
- agent执行AskDocument
- AskDocument执行结果的文本
1 | 2023年供应商月销售额任务管理方案.pdf |
step 2:
- 新提示词=原始提示词+上两轮提示词的结果,拼接在一起。
- LLM给出的决策文本
1 | { |
- agent执行
InspectExcel - 返回文本结果
react agent不怕大模型犯错,
思维链 Chain of Thought
用提示词引导到模型给出推理文字,然后再做任务
大模型无法反思只能一次输出内容,而agent有loop可以不断拼接提示词每次都让大模型输出内容可以达到反思的能。
agent平台
多模态
视觉与语言的打通
一个模型同时看懂语言和视觉,模型可以输出文字、也可以输出图片和视频,好处视觉转译文字、融合推理(融合图片的推理和文字推理)、视觉编辑。
视觉识别与视觉推理
传统视觉识别模型:没有推理、精度高、需要提前定义类型
- Yolo:目标识别,快
- Unet:具体区域的分割,慢
- 输入:1024*768图片
- 输出:1024*768图片,每一个像素都被标注属于哪个对象
- 优势:模型小、部署和使用成本低、识别精度高
- 劣势:需要单独标注、训练模型
多模态模型:有推理过程、精度低 - Gemini、GPT
- 优势:无需标注、无需训练、直接使用、有推理能力
- 劣势:部署成本高、精度低
视觉生成:人工智能生成内容(Artificial Intelligence Generated Content,简称AIGC)
模型能力不足时的综合方案。
能力不足:只写提示词给模型,生成的视频无法满足需求。
例如:
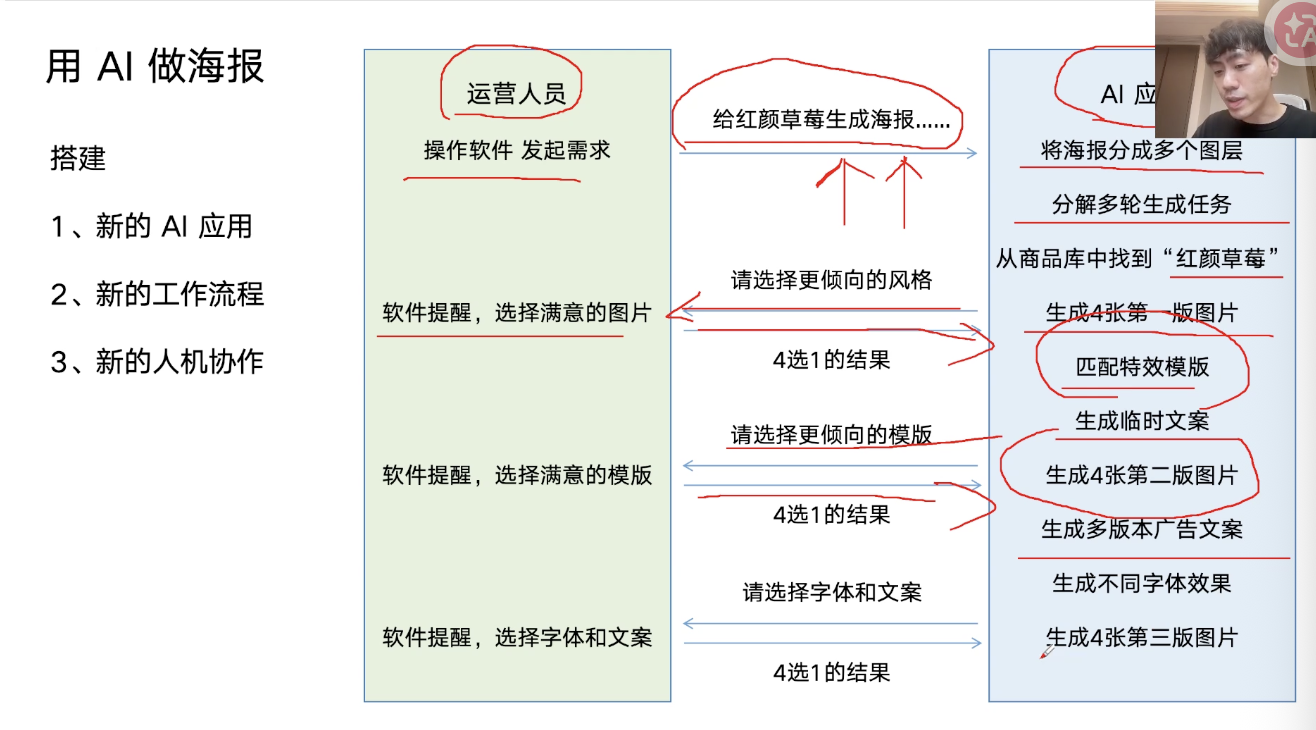
- 海报生成
- 漫剧:对象的一致性问题
- 电商视频
- 中长尾商品素材匮乏
- 爆款商品延展性差
- 内容需求量大,制作成本高
- 生产流程长,协同效率低
- 素材管理智能程度低
- 优质内容的筛选和复用难
- 效果反馈不及时
- 精细化内容营销难
电商视频生成
- 视频片段组合
- 由哪些片段组合的
- 这些片段哪来的
- 如何得到视频片段:品牌视频切片、产品展示切片、模特展示切片、直播切片
- AI+人工:json格式化切片
1 | { |
-
通过代码或工具,将视频中的音频分离
-
从音频中提取文字
-
通过多模态模型对画面进行文字描述
-
人工补充修改文字描述
-
整理成结构化信息
- 切片后的视频还需要配置结构化文字描述
- 打标签,你要自定义有哪些标签,不能让LLM瞎打标签。

-
用普通LLM不用多模态模型(因为每个片段都有丰富的结构化文本描述)排列、拼接视频片段。
- 渐进式批露:当提供的视频片段的结构文字数量很多时,让LLM规划视频内容,有多少条视频描述产品痛点、多少条产品描述、多少条促销,根据LLM挑选的各条视频+文字结构,然后排列,最后我们来实现视频的最终拼接。
-
生成内容
1、文生视频
2、图生视频
3、分析商家有什么(衣服)、没有什么(模特)
4、将衣服穿到模特身上,例如flux、catVTON,但是衣服穿到模特身上总是会出问题,例如衣服变形,穿着不到位。
catVTON局部重绘:将涂抹掉的区域重新绘制

涂抹不到位问题:
1、手动涂抹
2、对一个模特的涂抹区域打标签,例如短裤区域涂抹、7分裤区域涂抹、全身裤区域涂抹,图片+结构化文本。

3、为模特添加背景:人工+LLM梳理提示词模版 -
套模版
模型能力不足时的综合方案的评价
1、水涨船高型
2、擎天柱型


