
扩散模型
Denoising Diffusion Probabilistic Model (DDPM)
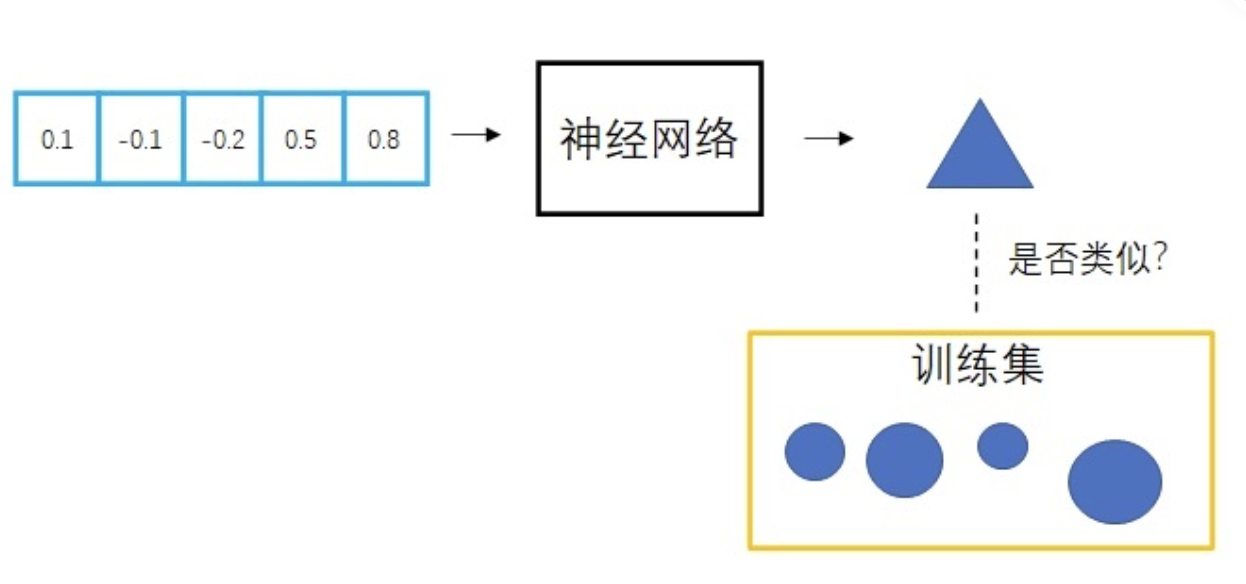
显然,为了生成丰富的图像,一个图像生成程序要根据随机数来生成图像。通常,这种随机数是一个满足标准正态分布的随机向量。这样,每次要生成新图像时,只需要从标准正态分布里随机生成一个向量并输入给程序就行了。生成图像的神经网络需要从数据中学习。对于图像生成任务,神经网络的训练数据一般是一些同类型的图片。比如一个绘制人脸的神经网络会用人脸照片来训练。也就是说,神经网络会学习如何把一个向量映射成一张图片,并确保这个图片和训练集的图片是一类图片。图像生成任务缺乏有效的指导,其他AI任务中,训练集本身会给出一个「标准答案」,指导AI的输出向标准答案靠拢。比如对于图像分类任务,训练集会给出每一幅图像的类别;对于人脸验证任务,训练集会给出两张人脸照片是不是同一个人;图像生成数据集里只有一些同类型图片,却没有指导AI如何画得更好的信息。
VAE(变分自编码器)
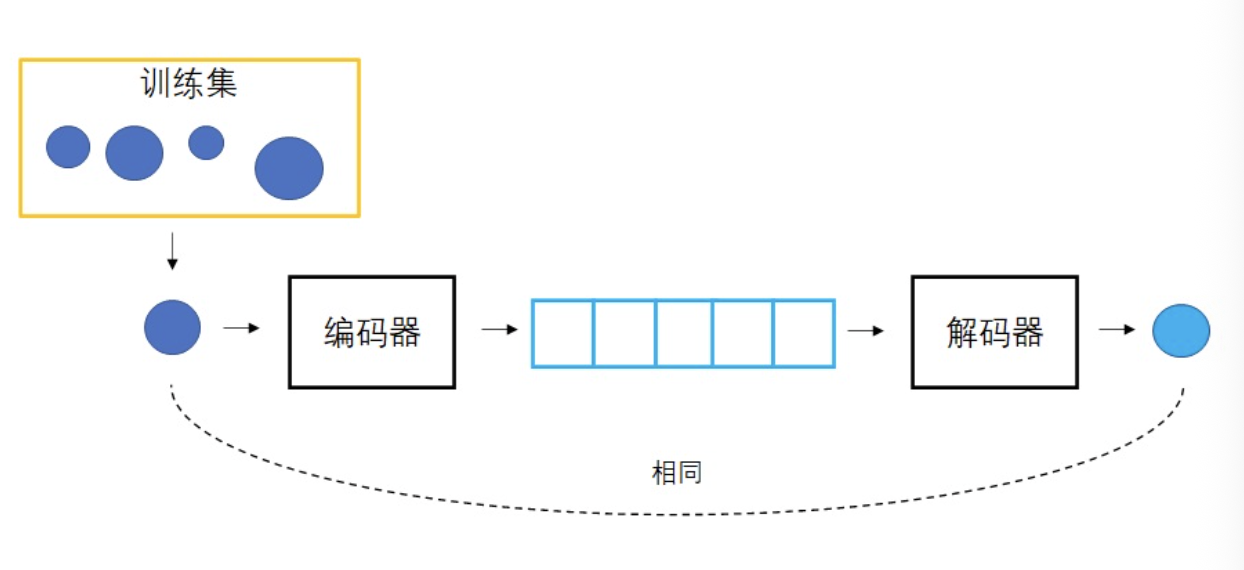
构成:编码器、概率潜在空间、解码器。在训练过程中,编码器预测每个图像的均值和方差。然后从高斯分布中对这些值进行采样,并将其传递到解码器中,其中输入的图像预计与输出的图像相似。这个过程包括使用KL Divergence来计算损失。
学习向量生成图像很困难,那就再同时学习怎么用图像生成向量。这样,把某图像变成向量,再用该向量生成图像,就应该得到一幅和原图像一模一样的图像。每一个向量的绘画结果有了一个标准答案,可以用一般的优化方法来指导网络的训练了。VAE中,把图像变成向量的网络叫做编码器,把向量转换回图像的网络叫做解码器。其中,解码器就是负责生成图像的模型。
GAN(生成对抗网络)
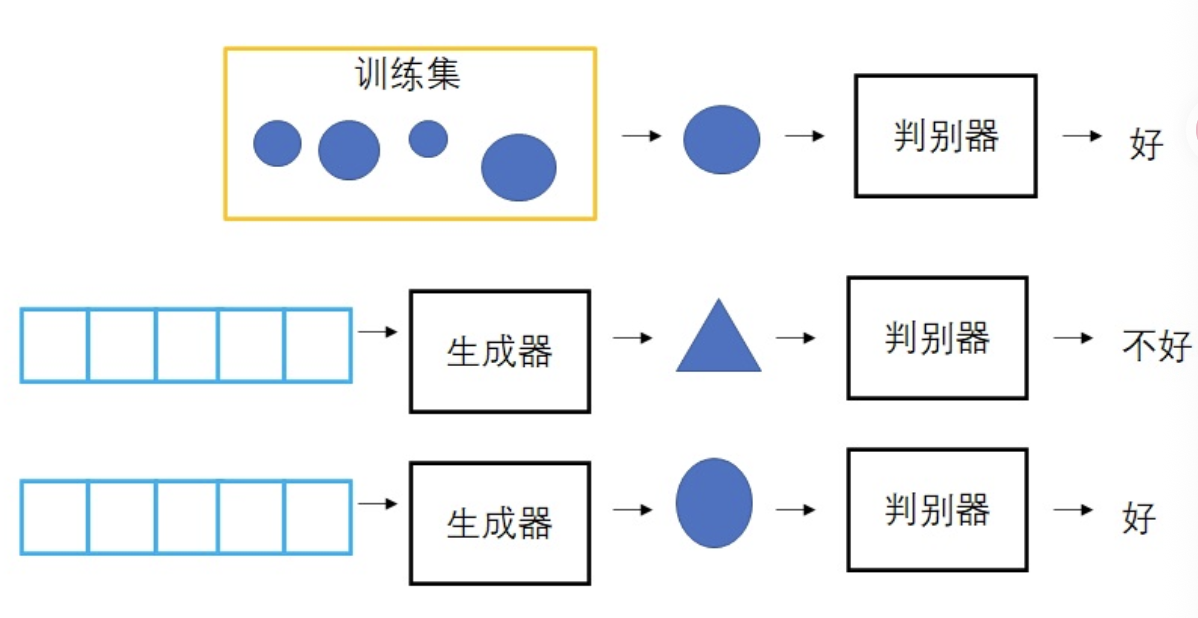
两个神经网络的协作:一个生成器和一个鉴别器,涉及对抗性训练过程。生成器的目标是从随机噪声中生成真实的数据,例如图像,而鉴别器则努力区分真实数据和生成数据。
DDPM
GANs擅长于生成与训练集中的图像非常相似的逼真图像,但VAEs擅长于创建各种各样的图像,尽管有产生模糊图像的倾向。DDPM创造出既高度逼真又多样化的图像。
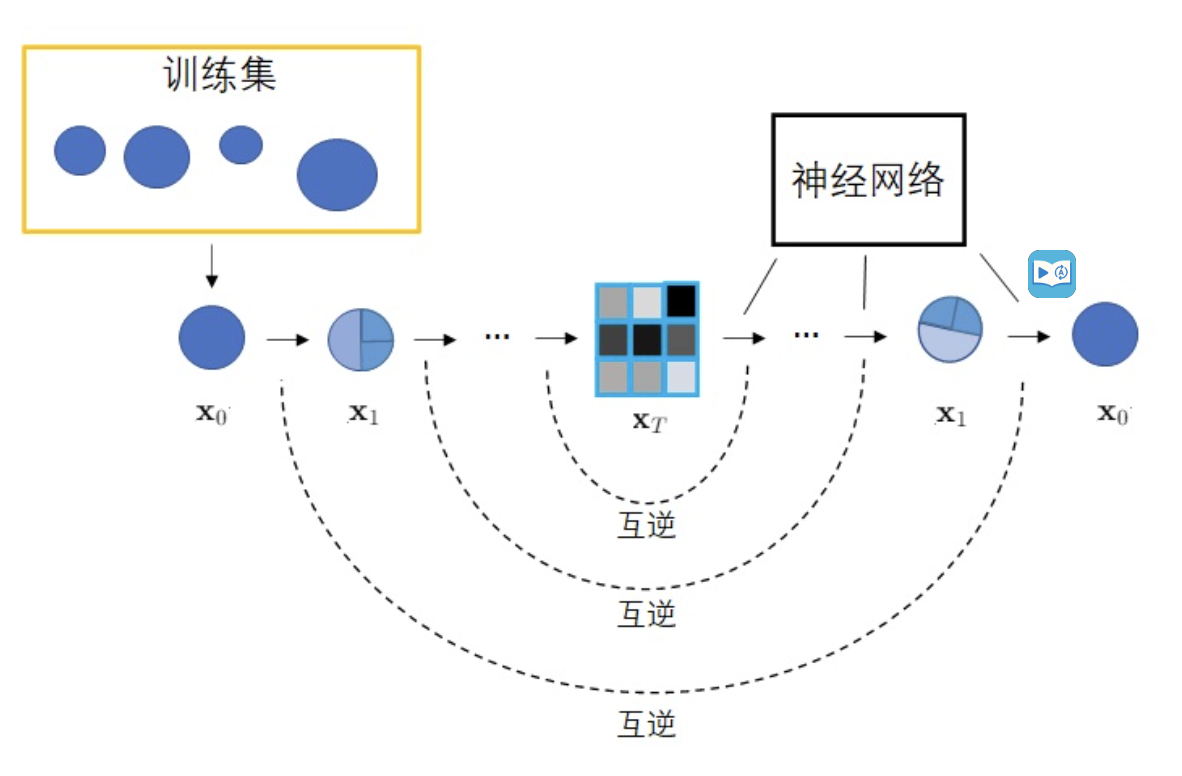
一个分布可以通过不断地添加噪声变成另一个分布,放到图像生成任务里,就是来自训练集的图像可以通过不断添加噪声变成符合标准正态分布的图像。我们可以对VAE做以下修改:1)不再训练一个可学习的编码器,而是把编码过程固定成不断添加噪声的过程;2)不再把图像压缩成更短的向量,而是自始至终都对一个等大的图像做操作。解码器依然是一个可学习的神经网络,它的目的也同样是实现编码的逆操作。不过,既然现在编码过程变成了加噪,那么解码器就应该负责去噪。而对于神经网络来说,去噪任务学习起来会更加有效。因此,扩散模型既不会涉及GAN中复杂的对抗训练,又比VAE更强大一点。
DDPM的训练包括两个基本步骤:产生噪声图像这是固定和不可学习的正向过程,以及随后的逆向过程。逆向过程的主要目标是使用专门的机器学习模型对图像进行去噪。
正向扩散过程

噪声是从高斯分布中采样的。为了在每一步引入少量的噪声,我们使用马尔可夫链。要生成当前时间戳的图像,我们只需要上次时间戳的图像。输入的$x_0$会不断混入高斯噪声,经过T次加噪声操作后,图像会变成一幅符合标准正态分布的纯噪声图像$x_T$。「加噪声」并不是给上一时刻的图像加上噪声值,而是从一个均值与上一时刻图像相关的正态分布里采样出一幅新图像$x_t \sim \mathcal{N}!\left(\mu_t(x_{t-1}),,\sigma_t^2,\mathit{I}\right)$。
马尔可夫链是一个随机过程,其中过渡到任何特定状态当前时刻的状态只由上一时刻的状态决定,而不由更早的状态决定。扩散模型通常把正态分布写成(重参数化(reparameterization)技巧)$$x_t\sim\mathcal{N}!\left(\sqrt{1-\beta_t},x_{t-1},\ \beta_t I\right)$$
$$\Rightarrow x_t=\sqrt{1-\beta_t},x_{t-1}+\sqrt{\beta_t},\epsilon_{t-1},其中\ \epsilon_{t-1}\sim \mathcal{N}(0,I)$$
用beta表示的方差参数被有意地设置为一个非常小的值,目的是在每个步骤中只引入最少量的噪声,步长参数“T”决定了生成全噪声图像所需的步长。如果已知 $x_{t−1}$,那么 $x_t$的采样值可以通过该公式生成。
往前推几步:
$$x_t=\sqrt{1-\beta_t} x_{t-1}+\sqrt{\beta_t}\epsilon_{t-1}$$
$$;;;;,=\sqrt{1-\beta_t}\left(\sqrt{1-\beta_{t-1}}x_{t-2}+\sqrt{\beta_{t-1}}\epsilon_{t-2}\right)+\sqrt{\beta_{t-1}}\epsilon_{t-1} $$
$$;;;;,=\sqrt{(1-\beta_t)(1-\beta_{t-1})}x_{t-2}+\sqrt{(1-\beta_t)\beta_{t-1}}\epsilon_{t-2}+\sqrt{\beta_t}\epsilon_{t-1}$$
$$;;;;, =\sqrt{(1-\beta_t)(1-\beta_{t-1})}x_{t-2}+\sqrt{(1-\beta_t)\beta_{t-1}+\beta_t}\epsilon$$
$$;;;;, =\sqrt{(1-\beta_t)(1-\beta_{t-1})}x_{t-2}+\sqrt{1-(1-\beta_t)(1-\beta_{t-1})}\epsilon$$
$$;;;;, =\sqrt{(1-\beta_t)(1-\beta_{t-1})(1-\beta_{t-2})}x_{t-3}+\sqrt{1-(1-\beta_t)(1-\beta_{t-1})(1-\beta_{t-2})}\epsilon$$
独立正态分布的加减公式
若 X ~ N(μ₁, σ₁²) 和 Y ~ N(μ₂, σ₂²) 且相互独立,则:
- 相加:X + Y ~ N(μ₁ + μ₂, σ₁² + σ₂²)。
- 相减:X - Y ~ N(μ₁ - μ₂, σ₁² + σ₂²)。
- 线形组合:$aX+bY∼N(aμ_1+bμ_2, a^2σ_1^2+b^2σ_2^2)$
令$\alpha_t = 1-\beta_t \quad \text{and} \quad \bar{\alpha}t=\prod{i=1}^{t} \alpha_t$
$$x_t=\sqrt{\bar{\alpha}_t}x_0+\sqrt{1-\bar{\alpha}_t},\epsilon$$
在DDPM论文中$\beta_t$是一个小于1的常数,$\beta_t$从$\beta_1=10^{-4}$到$\beta_T=0.02$线性增长。这样,$\beta_t$变大,$\alpha_t$也越小,$\bar{\alpha}_t$趋于0的速度越来越快,最后几乎为0,代入$x_T=\sqrt{\bar{\alpha}_T}x_0+\sqrt{1-\bar{\alpha}_T},\epsilon$, $x_T$就满足标准正态分布了,符合我们对扩散模型的要求。
逆向扩散过程
我们希望训练出一个神经网络,该网络能够学会T个去噪声操作,把$x_T$还原回$x_0$。网络的学习目标是让T个去噪声操作正好能抵消掉对应的加噪声操作。训练完毕后,只需要从标准正态分布里随机采样出一个噪声,再利用反向过程里的神经网络把该噪声恢复成一幅图像,就能够生成一幅图片了。
除非我们知道初始条件,即t = 0时的原始图像,否则无法从数学上实现对图像进行逆向处理去噪。我们的目标是直接从噪声中采样以创建新图像,这里缺乏关于结果的信息。所以我需要设计一种在不知道结果的情况下逐步去噪图像的方法。所以就出现了使用深度学习模型来近似这个复杂的数学函数的解决方案。
现在问题来了:去噪声操作的数学形式是怎么样的?怎么让神经网络来学习它呢?数学原理表明,当$\beta_t$足够小时,每一步去噪声(加噪声的逆操作)也满足正态分布
$x_{t-1}\sim \mathcal{N}(\tilde{\mu}_t,\tilde{\beta}_tI)$。当前时刻去噪的均值$\tilde{\mu}_t$和方差$\tilde{\beta}_t$由当前的时刻t、当前的图像$x_t$决定。因此,为了描述所有去噪声操作,神经网络应该输入t、$x_t$,拟合当前的均值$\tilde{\mu}_t$和方差$\tilde{\beta}_t$。去噪声操作和加噪声逆操作的关系,就是神经网络的预测值和真值的关系。
现在问题来了:加噪声逆操作的均值和方差是什么?, 加噪声逆操作的真值(均值、方差)需要通过贝叶斯公式、前向公式计算得到。
直接计算所有数据的加噪声逆操作的分布是不太现实的。但是,如果给定了某个训练集输入$x_0$,多了一个限定条件后,该分布是可以用贝叶斯公式计算的(其中q表示概率分布):
$$q(x_{t-1}\mid x_t, x_0)= q(x_t\mid x_{t-1},x_0)\frac{q(x_{t-1}\mid x_0)}{q(x_t\mid x_0)}$$
等式左边的后验分布$q(x_{t-1}|x_t,x_0)=\mathcal{N}(x_{t-1};\tilde{\mu}t,\tilde{\beta}tI)$(均值为 $\tilde{\mu}_t$、协方差为$\tilde{\beta}t$的高斯分布,在$x{t-1}$处的概率密度值)表示加噪声操作的逆操作,它的均值和方差都是待求的。右边的似然分布$q(x{t}|x{t-1},x_0)=\mathcal{N}(x_{t};\sqrt{1-\beta_t}x_{t-1},\beta_tI)$(前向过程马尔可夫只考虑$x_{t-1}$的分布,或者认为$\sqrt{\bar{\alpha}_t}x_0+\sqrt{1-\bar{\alpha}t},\epsilon$的分布是个小量)是加噪声的分布。而由于$x_0$已知,先验分布$q(x{t-1}\mid x_0)$和$q(x_t\mid x_0)$两项可以根据前面的公式$x_t=\sqrt{\bar{\alpha}_t}x_0+\sqrt{1-\bar{\alpha}_t},\epsilon$得来:
$$q(x_{t}\mid x_0)=\mathcal{N}(x_t;\sqrt{\bar{\alpha}_t}x_0,(1-\bar{\alpha}_t)I)$$
$$q(x_{t-1}\mid x_0)=\mathcal{N}(x_{t-1};\sqrt{\bar{\alpha}{t-1}}x_0,(1-\bar{\alpha}{t-1})I)$$
由上述贝叶斯公式中的等号右侧已知分布推导等号左侧分布的均值$\tilde{\mu}_t$和方差$\tilde{\beta}_t$
步骤1:写出各个密度(忽略归一化常数)
$$q(x_t\mid x_{t-1},x_0)\propto \exp!\left(-\frac{\left\lVert x_t-\sqrt{\alpha_t},x_{t-1}\right\rVert^2}{2\beta_t}\right)$$
$$q(x_{t-1}\mid x_0)\propto \exp!\left(-\frac{\left\lVert x_{t-1}-\sqrt{\bar{\alpha}{t-1}},x_0\right\rVert^2}{2(1-\bar{\alpha}{t-1})}\right)$$
$$q(x_t\mid x_0)\propto \exp!\left(-\frac{\left\lVert x_t-\sqrt{\bar{\alpha}_t},x_0\right\rVert^2}{2(1-\bar{\alpha}_t)}\right)$$
对于$x_{t-1}$变量来说此表达式中$x_t$是常数所以$q(x_{t}\mid x_0)$也是常数(因为分母与 $x_{t−1}$无关), 它不会影响形状,只需在最后归一化。
$$q(x_{t-1}\mid x_t,x_0)\propto \exp!\left(-\frac{\left\lVert x_t-\sqrt{\bar{\alpha}t},x{t-1}\right\rVert^2}{2\beta_t}-\frac{\left\lVert x_{t-1}-\sqrt{\bar{\alpha}{t-1}},x_0\right\rVert^2}{2(1-\bar{\alpha}{t-1})}\right)$$
步骤2:展开指数中的二次型
第一项:$$ \left|x_t-\sqrt{\alpha_t},x_{t-1}\right|^2 = \left|x_t\right|^2 -2\sqrt{\alpha_t} x_t^\mathsf{T}x_{t-1} +\alpha_t\left|x_{t-1}\right|^2$$
第二项: $$\left|x_{t-1}-\sqrt{\bar{\alpha}t},x_0\right|^2=\left|x{t-1}\right|^2-2\sqrt{\bar{\alpha}t},x_0^{\mathsf{T}}x{t-1}+\bar{\alpha}_{t-1},\left|x_0\right|^2$$
将指数合并,提取 $x_{t−1}$的二次项和一次项系数。
二次项系数:[-\frac{1}{2\beta_t}\cdot \alpha_t-\frac{1}{2(1-\bar{\alpha}{t-1})}\cdot 1= -\frac{1}{2}\left(\frac{\alpha_t}{\beta_t}+\frac{1}{1-\bar{\alpha}{t-1}}\right)]
一次项系数:[-\frac{1}{2\beta_t}\cdot\left(-2\sqrt{\alpha_t},x_t^\mathsf{T},x_{t-1}\right);+;\frac{-1}{2\left(1-\alpha_{t-1}\right)}\cdot\left(-2\sqrt{\bar{\alpha}{t-1}},x_0^\mathsf{T},x{t-1}\right)=\frac{\sqrt{\alpha_t}}{\beta_t}x_t^\mathsf{T}x_{t-1}+\frac{\sqrt{\overline{\alpha}{t-1}}}{1-\overline{\alpha}{t-1}}x_0^\mathsf{T},x_{t-1}]
步骤3:配成高斯形式,求协方差
高斯密度关于 $x_{t−1}$ 的标准形式为:
$$\exp\left(-\frac12(x_{t-1}-\mu)^\top\Sigma^{-1}(x_{t-1}-\mu)\right)=\exp\left(-\frac12 x_{t-1}^\top\Sigma^{-1}x_{t-1}+\mu^\top\Sigma^{-1}x_{t-1}+\text{常数}\right)$$
$$\Sigma^{-1}=\left(\frac{\alpha_t}{\beta_t}+\frac{1}{1-\bar{\alpha}_{t-1}}\right)I$$
协方差矩阵:$$\Sigma=\tilde{\beta}tI, \tilde{\beta}t=\frac{1}{\frac{\alpha_t}{\beta_t}+\frac{1}{1-\bar{\alpha}{t-1}}}=\frac{(1-\bar{\alpha}{t-1})}{1-\bar{\alpha}_t}\beta_t$$
步骤4:求均值 $\tilde{\mu}_t$
$$\tilde{\mu}t^\top\Sigma^{-1}=\frac{\sqrt{\alpha_t}}{\beta_t}x_t^\mathsf{T}+\frac{\sqrt{\overline{\alpha}{t-1}}}{1-\overline{\alpha}_{t-1}}x_0^\mathsf{T}$$以及$\Sigma^{-1}=\frac{1}{\tilde{\beta}_t}I$
$$\tilde{\mu}t=\frac{\sqrt{\alpha_t}\left(1-\bar{\alpha}{t-1}\right)}{1-\bar{\alpha}t}x_t+\frac{\sqrt{\bar{\alpha}{t-1}}\beta_t}{1-\bar{\alpha}_t}x_0$$
步骤5:转换为用噪声 $\epsilon_t$的表示的形式
由于$x_t=\sqrt{\bar{\alpha}_t}x_0+\sqrt{1-\bar{\alpha}_t}\epsilon_t$
$$\tilde{\mu}_t=\frac{1}{\sqrt{\alpha}_t}(x_t-\frac{1-\alpha_t}{\sqrt{1-\bar{\alpha}_t}}\epsilon_t)$$
注意,$\beta_t$是加噪声的方差,是一个常量。那么,加噪声逆操作的方差$\tilde{\beta}_t$也是一个常量,不与输入$x_0$相关。训练去噪网络时,神经网络只用拟合个均值就行,不用再拟合方差了。
损失函数
知道了均值和方差的真值$\tilde{\mu}_t$、$\tilde{\beta}_t$,训练神经网络只差最后的问题了:该怎么设置训练的损失函数?
加噪声逆操作和去噪声操作都是正态分布,网络的训练目标应该是让每对正态分布更加接近。用损失函数描述两个分布尽可能接近呢?
目标均值为$$\tilde{\mu}_t=\frac{1}{\sqrt{\alpha}t}(x_t-\frac{1-\alpha_t}{\sqrt{1-\bar{\alpha}t}}\epsilon_t)$$神经网络拟合均值时,$x_t$是已知的(别忘了,图像是一步一步倒着去噪的),式子里唯一不确定的只有$\epsilon_t$。既然如此,神经网络干脆也别预测均值了,直接预测一个噪声$\epsilon\theta(x_t,t)$(其中$\theta$为可学习参数),让它和生成$x_t$的噪声$\epsilon_t$的均方误差最小就行,单轮训练误差函数$L=\left\Vert\epsilon_t-\epsilon\theta(x_t,t)\right\Vert^2$。神经网络的学习目标就是让其输出的去噪声分布和理论计算的加噪声逆操作分布一致。
训练与采样算法
正向加噪并用神经网络学习噪声,我们虽然要求神经网络拟合个正态分布,但实际训练时,不用一轮预测个结果,只需要随机预测个时刻中某一个时刻的结果就行。

反向去噪用学习的神经网络的噪声分布生成图像,第一行的$x_t$就是从标准正态分布里随机采样的输入噪声。要生成不同的图像,只需要更换这个噪声。令时刻T从到1,计算这一时刻去噪声操作的均值和方差,并采样出$x_{t-1}$。
方差的选择:
[
\sigma_t=
\begin{cases}
\frac{1-\bar{\alpha}_{t-1}}{1-\bar{\alpha}_t}\cdot\beta_t&,当x_0是特定数据时 \
;;;;;;;\beta_t &, 当x_0\sim\mathcal{N}(0,I)时
\end{cases}
]



