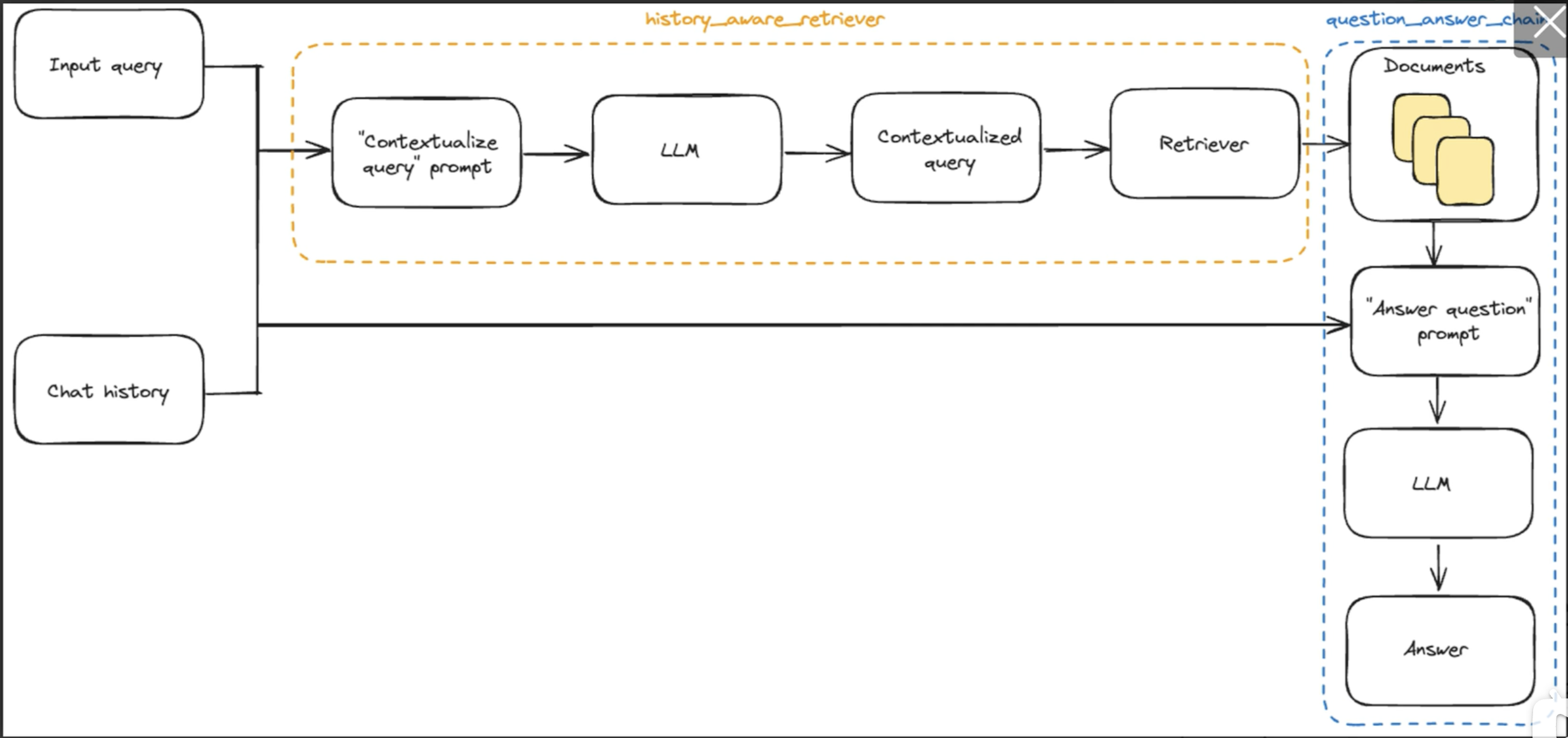
数据描述文件dataset_info.json "dataset_name": { "hf_hub_url": "the name of the dataset repository on the Hugging Face hub. (if specified, ignore script_url and file_name)", "ms_hub_url": "the name of the dataset repository on the Model Scope hub. (if specified, ignore script_url and file_name)", "script_url": "the name of the directory containing a dataset loading script. (if specified, ignore file_name)", "file_name": "the name of the dataset folder or dataset file in this directory. (required if above are not specified)", "formatting": "the format of the dataset. (optional, default: alpaca, can be chosen from {alpaca, sharegpt})", "ranking": "whether the dataset is a preference dataset or not. (default: False)", "subset": "the name of the subset. (optional, default: None)", "split": "the name of dataset split to be used. (optional, default: train)", "folder": "the name of the folder of the dataset repository on the Hugging Face hub. (optional, default: None)", "num_samples": "the number of samples in the dataset to be used. (optional, default: None)", "columns (optional)": { "prompt": "the column name in the dataset containing the prompts. (default: instruction)", "query": "the column name in the dataset containing the queries. (default: input)", "response": "the column name in the dataset containing the responses. (default: output)", "history": "the column name in the dataset containing the histories. (default: None)", "messages": "the column name in the dataset containing the messages. (default: conversations)", "system": "the column name in the dataset containing the system prompts. (default: None)", "tools": "the column name in the dataset containing the tool description. (default: None)", "images": "the column name in the dataset containing the image inputs. (default: None)", "videos": "the column name in the dataset containing the videos inputs. (default: None)", "audios": "the column name in the dataset containing the audios inputs. (default: None)", "chosen": "the column name in the dataset containing the chosen answers. (default: None)", "rejected": "the column name in the dataset containing the rejected answers. (default: None)", "kto_tag": "the column name in the dataset containing the kto tags. (default: None)" }, "tags (optional, used for the sharegpt format)": { "role_tag": "the key in the message represents the identity. (default: from)", "content_tag": "the key in the message represents the content. (default: value)", "user_tag": "the value of the role_tag represents the user. (default: human)", "assistant_tag": "the value of the role_tag represents the assistant. (default: gpt)", "observation_tag": "the value of the role_tag represents the tool results. (default: observation)", "function_tag": "the value of the role_tag represents the function call. (default: function_call)", "system_tag": "the value of the role_tag represents the system prompt. (default: system, can override system column)" } }
[ { "instruction":"Classify the following sentence as either an opinion or fact.", "input":"A hot dog is just one of many types of processed meat you can eat.", "output":"Fact." }, { "instruction":"Format and organize the following unstructured text information into a table.", "input":"Name: Peter\nAge: 43\nGender: Male\nOccupation: Doctor", "output":"| Category | Information |\n|------------|-------------|\n| Name | Peter |\n| Age | 43 |\n| Gender | Male |\n| Occupation | Doctor |" }, { "instruction":"Given the following array, print out maximum value in descending order. \n\n[4, 8, 0, 9, 15]", "input":"[4, 8, 0, 9, 15]", "output":"15\n9\n8\n4\n0", "history":[ ["print out minimum value in increasing order","0\n4\n8\n9\n15"] ] } { "instruction":"判断在频谱数据中是否存在故障,工况条件为:。。。,并给出详细故障内容" "input":"0Hz至4Hz振动有效值为:0.7313359070982054, 5Hz至9Hz振动有效值为:0.5516794943665811, 10Hz至14Hz振动有效值为:0.64766006489319, 15Hz至19Hz振动有效值为:3.0707501463193583, 20Hz至24Hz振动有效值为:0.6548395850417195, 25Hz至29Hz振动有效值为:0.26479291295984514, 30Hz至34Hz振动有效值为:0.4057607491630266, 35Hz至39Hz振动有效值为:0.3412169025400324, 40Hz至44Hz振动有效值为:0.19167337178728241, 45Hz至49Hz振动有效值为:0.20967801201261643,50Hz至54Hz振动有效值为:0.2543538684896362" "output":"存在故障,故障特征为:。。。", "history":[ [ "55Hz至59Hz振动有效值为:0.6280184736095086, 60Hz至64Hz振动有效值为:0.3123565814013977, 65Hz至69Hz振动有效值为:0.2982322812970321, 70Hz至74Hz振动有效值为:0.2523941314035457, 75Hz至79Hz振动有效值为:1.0019673960653408, 80Hz至84Hz振动有效值为:0.38334371478931645, 85Hz至89Hz振动有效值为:0.40893629328147063, 90Hz至94Hz振动有效值为:1.1188524730758498, 95Hz至99Hz振动有效值为:0.819641930908284, 100Hz至104Hz振动有效值为:0.5804811401893758, 105Hz至109Hz振动有效值为:0.21268042122054098, 110Hz至114Hz振动有效值为:0.2152073347988916, 115Hz至119Hz振动有效值为:0.3527403211644723","不存在故障,原因为:。。。" ], ] } ]
[ { "text":"Don’t think you need all the bells and whistles? No problem. McKinley Heating Service Experts Heating & Air Conditioning offers basic air cleaners that work to improve the quality of the air in your home without breaking the bank. " }, { "text":"To the apparent surprise of everyone, the Walt Disney Company has announced a deal to purchase Lucasfilm Ltd. } ]
[ { "conversations":[ { "from":"human", "value":"Hi, I have some ingredients and I want to cook something. Can you help me find a recipe?" }, { "from":"gpt", "value":"Of course! I can help you with that. Please tell me what ingredients you have." }, { "from":"human", "value":"I have chicken, bell peppers, and rice." }, { "from":"function_call", "value":"{\"name\": \"search_recipes\", \"arguments\": {\"ingredients\": [\"chicken\", \"bell peppers\", \"rice\"]}}" }, { "from":"observation", "value":"{\"recipes\": [{\"name\": \"Chicken and Bell Pepper Stir Fry\", \"ingredients\": [\"chicken\", \"bell peppers\", \"rice\"], \"instructions\": \"Cut the chicken into small pieces. Slice the bell peppers. Cook the rice. Stir fry the chicken and bell peppers. Serve over rice.\"}, {\"name\": \"Chicken and Rice Casserole\", \"ingredients\": [\"chicken\", \"bell peppers\", \"rice\"], \"instructions\": \"Cook the chicken and rice separately. Mix them together with the bell peppers in a casserole dish. Bake until golden brown.\"}]}" }, { "from":"gpt", "value":"I found two recipes for you. The first one is \"Chicken and Bell Pepper Stir Fry\". The instructions are: Cut the chicken into small pieces. Slice the bell peppers. Cook the rice. Stir fry the chicken and bell peppers. Serve over rice. The second one is \"Chicken and Rice Casserole\". The instructions are: Cook the chicken and rice separately. Mix them together with the bell peppers in a casserole dish. Bake until golden brown. Which one would you like to try?" }, { "from":"human", "value":"They both sound delicious, but I think I'll try the stir fry. Can you order the ingredients for me?" }, { "from":"gpt", "value":"I'm sorry, but as an AI, I don't have the capability to perform external tasks such as ordering ingredients. However, I can help you find more recipes or provide cooking tips if you need." } ], "tools":"[{\"name\": \"search_recipes\", \"description\": \"Search for recipes based on ingredients\", \"parameters\": {\"type\": \"object\", \"properties\": {\"ingredients\": {\"type\": \"array\", \"items\": {\"type\": \"string\"}, \"description\": \"The ingredients to search for\"}}, \"required\": [\"ingredients\"]}}]" }, { "conversations":[ { "from":"human", "value":"Write a definition of \"photoshop\"." }, { "from":"gpt", "value":"Photoshop is a software application developed by Adobe that enables users to manipulate digital images by providing a variety of tools and features to alter, enhance, and edit photos. It allows users to adjust the color balance, contrast, and brightness of images, remove backgrounds, add or remove elements from images, and perform numerous other image manipulation tasks. Photoshop is widely used by graphic designers, photographers, and digital artists for creating and enhancing images for a variety of purposes, including print and online media." }, { "from":"human", "value":"Can you explain the difference between machine learning and deep learning?" }, { "from":"gpt", "value":"Machine learning is a subset of artificial intelligence that involves the use of algorithms to analyze and learn from data, without being explicitly programmed. It enables computers to identify patterns in data, make decisions based on those patterns, and improve performance over time by learning from experience.\n\nDeep learning, on the other hand, is a subset of machine learning that involves the use of neural networks to learn from data. These neural networks are composed of multiple layers of interconnected nodes, and they can be trained on large datasets to recognize patterns and correlations in data. Deep learning has been particularly successful in image recognition, speech recognition, and natural language processing tasks.\n\nOne way to think about the difference between the two is that machine learning relies on statistical models and algorithms to make predictions, while deep learning uses neural networks to mimic the structure of the human brain and achieve higher levels of accuracy and complexity in its predictions." }, { "from":"human", "value":"How does blockchain work?" }, { "from":"gpt", "value":"Blockchain is a decentralized digital ledger technology that allows multiple parties to maintain a shared and tamper-proof record of transactions and information. Each block in the chain contains a cryptographic hash of the previous block, along with new data and a unique identifier, which creates an unbreakable chain of blocks that cannot be altered or deleted without consensus from the network.\n\nWhen a transaction is initiated on the blockchain, it is broadcast to all nodes on the network, which validate and verify the transaction using complex cryptographic algorithms. Once validated, the transaction is added to the blockchain and becomes a permanent part of the ledger.\n\nThe decentralized nature of blockchain means that there is no single point of failure or control, and the system is highly secure and transparent. This makes it ideal for use cases such as cryptocurrency transactions, supply chain management, and identity verification." }, { "from":"human", "value":"Can you explain what quantum computing is?" }, { "from":"gpt", "value":"Quantum computing is a type of computing technology that uses the principles of quantum mechanics to perform complex calculations and solve problems that are currently beyond the capabilities of classical computers. Unlike classical computers, which use bits to represent information as either 0 or 1, quantum computers use qubits, which can exist in multiple states simultaneously.\n\nThis allows quantum computers to perform certain types of calculations much faster than classical computers, such as factoring large numbers, simulating complex chemical reactions, and searching through large databases. Quantum computing also has the potential to revolutionize fields such as cryptography, machine learning, and drug discovery.\n\nHowever, quantum computing is still in its early stages of development, and there are many technical challenges that need to be overcome before it can become a practical technology. These include improving the stability and reliability of qubits, developing error correction algorithms, and scaling up the size and complexity of quantum systems." }, { "from":"human", "value":"What is the difference between AR and VR?" }, { "from":"gpt", "value":"Augmented reality (AR) and virtual reality (VR) are both technologies that provide immersive and interactive experiences, but they differ in how they create those experiences.\n\nAR overlays digital information onto the real world, typically using a camera or other sensors to track the user's environment and position. This allows users to interact with digital objects and information while still being aware of their physical surroundings. Examples of AR applications include games, navigation apps, and marketing campaigns.\n\nVR, on the other hand, creates a completely simulated environment that users can enter and interact with using specialized headsets and controllers. This allows users to experience completely new worlds and environments, and can be used for everything from gaming and entertainment to education and training.\n\nWhile both AR and VR have their own unique strengths and applications, they are often used together in what is known as mixed reality (MR), which combines the real and virtual worlds to create even more immersive and interactive experiences." } ], "tools":"[]" } ]
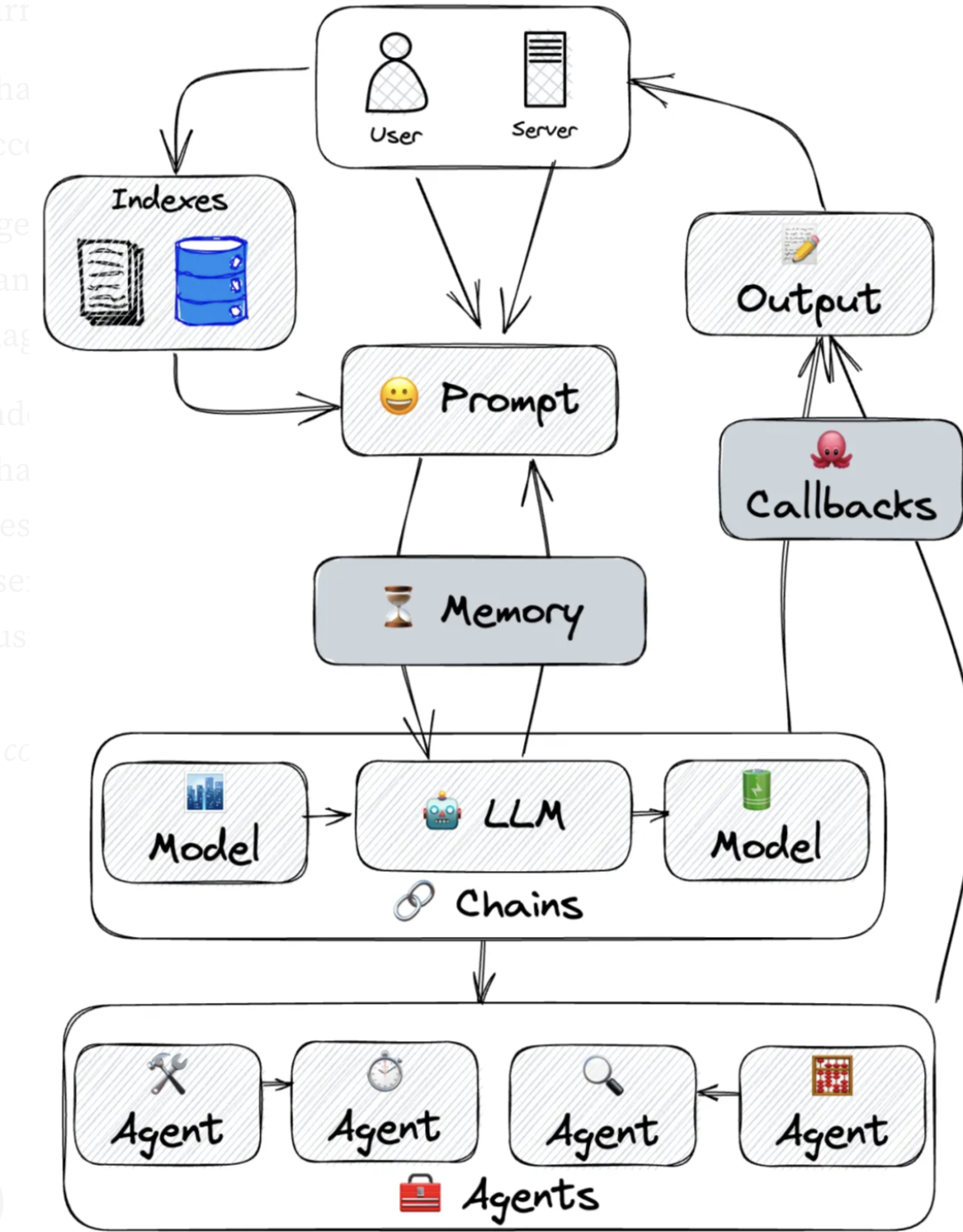
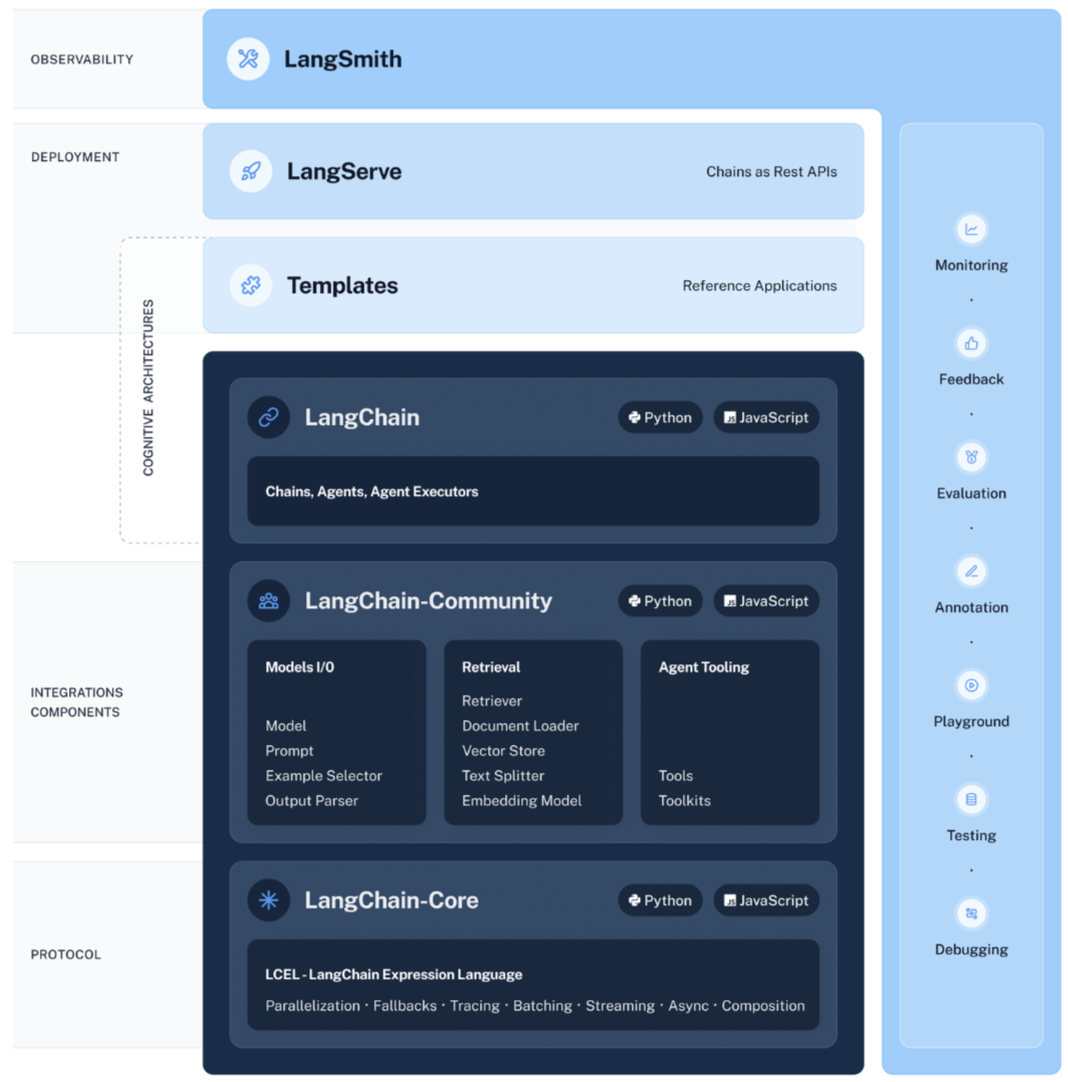
#tools_searcher.py from langchain_community.tools.tavily_search import TavilySearchResults search = TavilySearchResults() search.invoke("what is the weather in SF")
#tools_retriever.py from langchain_community.document_loaders import WebBaseLoader from langchain_community.vectorstores import FAISS from langchain_openai import OpenAIEmbeddings from langchain_text_splitters import RecursiveCharacterTextSplitter from langchain.tools.retriever import create_retriever_tool
loader = WebBaseLoader("https://docs.smith.langchain.com/overview") docs = loader.load() documents = RecursiveCharacterTextSplitter( chunk_size=1000, chunk_overlap=200 ).split_documents(docs) #生成向量库 vector = FAISS.from_documents(documents, OpenAIEmbeddings()) retriever = vector.as_retriever() #检索信息 retriever.invoke("how to upload a dataset")[0] #封装检索工具 retriever_tool = create_retriever_tool( retriever, "langsmith_search", "Search for information about LangSmith. For any questions about LangSmith, you must use this tool!", )
#agent_tools_create.py from langchain_openai import ChatOpenAI from .tools_searcher import search from .tools_retriever import retriever_tool
model = ChatOpenAI(model="gpt-4") tools = [search, retriever_tool] #获取提示 from langchain import hub #为agent设计提示词模版 prompt = hub.pull("hwchase17/openai-functions-agent") print(prompt.messages) #创建代理, 大模型根据提示词语义决策调用哪个工具,由agent执行具体的工具 from langchain.agents import create_tool_calling_agent agent = create_tool_calling_agent(model, tools, prompt)
from langchain.agents import AgentExecutor agent_executor = AgentExecutor(agent=agent, tools=tools)
#消息存储 from langchain.community.chat_message_histories import ChatMessageHistroy from langchain_core.chat_history import BaseChatMessageHistory from langchain_core.runnables.history import RunnableWithMessageHistroy #回话隔离,每个回话窗口有自己的历史聊天